
How to detect un-process files in hadoop development with Python, HBase, and Pig
In this post, hadoop development professionals are sharing guide that helps in detecting un-process data files in HDFS system with Python, Pig, and HBase. You can read this post and find the way to detect such files.
In the real big data application, we need to process the data hourly or daily. Therefore, we need a solution to detect which data file we already process, this work will reduce process time and we will not have the duplication in our processed data set.
Environment : Java: JDK 1.7
Cloudera version: CDH5.4.7, please refer to this link: http://www.cloudera.com/downloads/cdh/5-4-7.html
Initial steps
1. We need to prepare some input data files, open the file with vi tool to create a local file:
-
vi file1
- Jack
- Ryan
- Jean
-
Vi file2
- Candy
- Bill
2. We need to put the local files to Hadoop Distributed File System (HDFS), use this command:
3. Create the HBase table to store the last processed time.

Code walk through
This is pig script to load the data and just simple dump the data to command line to prove that we only process new files.
Note: Please note that this pig script will compile to Map Reduce Job to store the data to HBase in parallel.
This is Python script which using Hadoop, HBase and Pig libraries to detect unprocess files and pass files to Pig script:
- 0. We need to import org.apache.hadoop.* and org.apache.pig.* packagein Python script.
- 1. Access to HBase to get the latest time which we already processed data.
- 2. We will loop and check the modification time of all files in input HDFS location with the value from HBase data.
- 3. If the value from files is greater than the value from HBase, we will add the file to a list unprocess file and pass this file list to Pig to process the data. If the value from files is less than 0, we will stop the Map Reduce Job because we do not have any new files to process.
- 4. We will update the latest process file to HBase again to use in the future.
Verify the result
0. Run script with this command:
pig checkLatestProcessedFile.py
1. The log file when the Map Reduce job finished
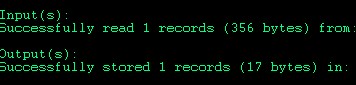
2. At the first time, when we put two sample files, you can see Pig only pick two files to process and dump the output data.
3. You can verify the lastest processed time in HBase by this command:

4. Once we processed the data, we will run the code again without any new file, we will got the message like the picture below and the script will be stopped:

5. Now we need to verify the new file coming as “file3”, we can create a new file and put to HDFS with same steps in “Initial Steps” part
6. Now we can run the script again at the step 1, we will see that only file3 will be processed in pig script.
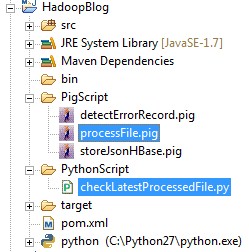
7. The structure of project should be like this, we need two bold file in the picture:
hadoop development experts hope this guide will help in detecting un-process files in HDFS with Python, HBase, and Pig. You can also read about Pig, HBase, and Python to understand the process better. If you have any query, ask them and clear your doubts.
We hope this blog will help you guys can detect un-process files to process. We will not have duplication data when processing raw data.